CV
Publications
Projects
Robots
Taekyung Kim | @tkkim-robot
/
Projects
Taekyung Kim | @tkkim-robot
/
Projects
CV
Publications
Projects
Robots
Projects
Project Pages
We revisit three
backup-based safety filters
—
Backup CBF
,
Model Predictive Shielding (MPS)
, and
gatekeeper
—under a common safety-filter abstraction. All three methods share the same backbone: when the nominal controller becomes risky, they rely on a backup policy that keeps the system safe and steers it to a terminal controlled invariant set.
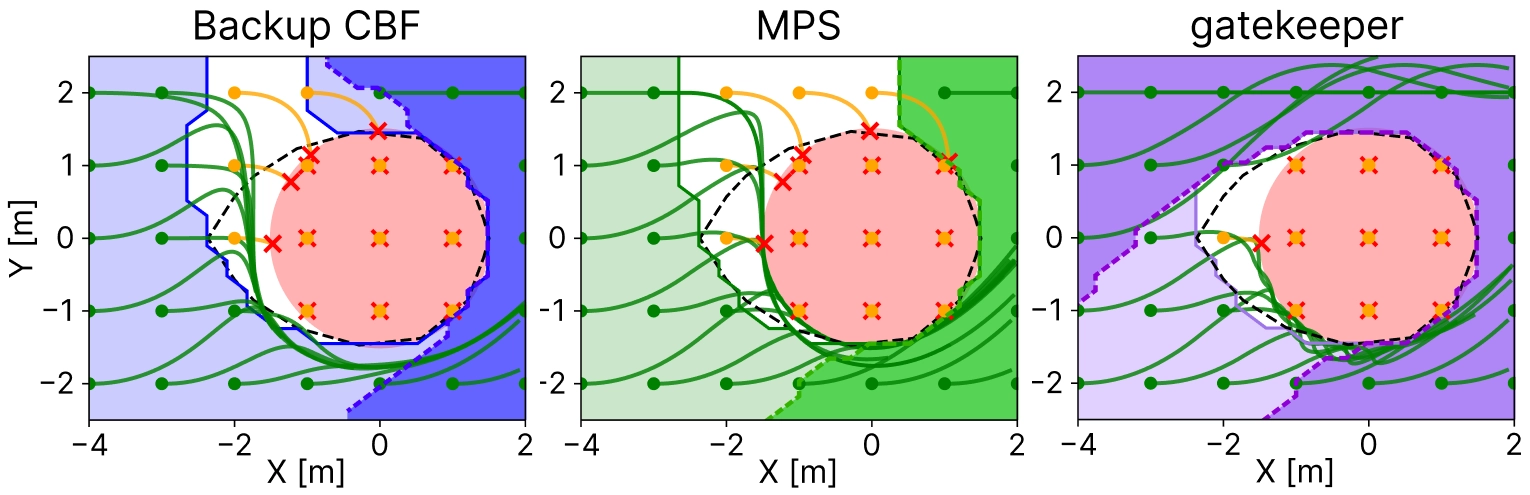
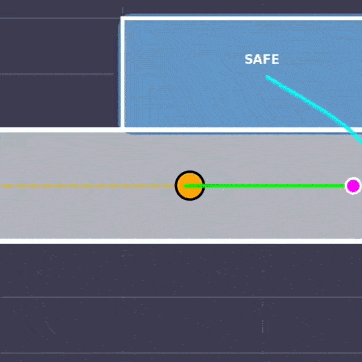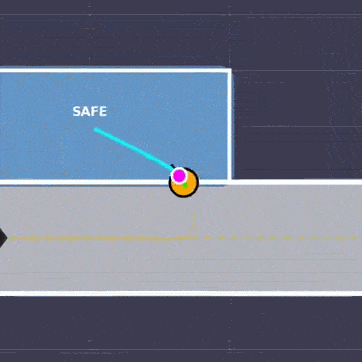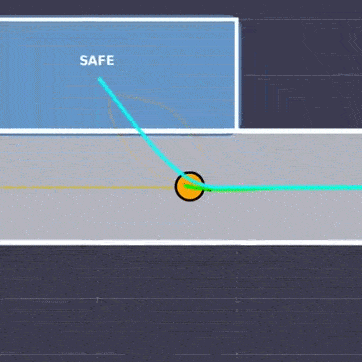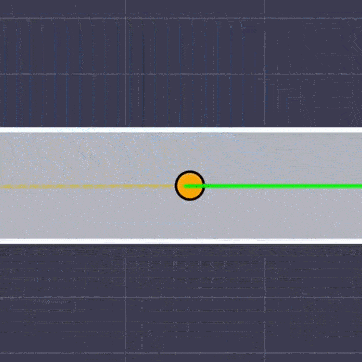
Recovered safe sets (light-colored regions) and filter-inactive sets (dark-colored regions) for the planar double-integrator example. The dashed black curve denotes the viability kernel. Backup CBF and MPS intervene earlier because safety is certified through an immediate or near-immediate commitment to backup, whereas gatekeeper enlarges the nominal-acceptance region by searching over the switching time.
This is a compact tutorial and comparative review paper. It clarifies the theoretical connections among Backup CBF, MPS, and gatekeeper, and explains when the three methods agree, differ, and intervene unnecessarily.
Review of Backup-Based Safety Filters
Overview diagram of the Safe Model Predictive Diffusion (Safe MPD) algorithm. The forward process (top) gradually adds noise to an optimal trajectory. The backward (denoising) process (bottom) iteratively refines a random trajectory into an optimal solution. At each step, we generate K candidate trajectories. Our
Shielded Rollout
mechanism transforms
every candidate
into a
kinodynamically feasible and provably safe trajectory
before the Monte Carlo score ascent step.
We present
Safe Model Predictive Diffusion (Safe MPD)
, a training-free diffusion planner for generating
provably safe
and
kinodynamically feasible
trajectories. Our algorithm integrates a
safety shield
directly into the denoising process of a model-based diffusion framework. By enforcing feasibility and safety on every sample throughout the denoising process, our method
avoids the common pitfalls of
post-processing corrections
, such as computational intractability and loss of feasibility. Through a parallelization in GPU, our method achieves
sub-second
planning times
even on challenging, non-convex problems.
Motivation
[ICRA 2026] Safe Model Predictive Diffusion
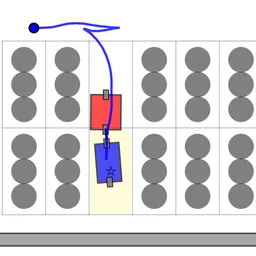
Illustration of the DPCBF mechanism in dynamic obstacle avoidance
We propose a
Dynamic Parabolic Control Barrier Function (DPCBF)
for nonholonomic robots in dynamic obstacle avoidance tasks. By dynamically shaping its safety boundary based on the distance to and relative velocity of an obstacle, our method provides a
less conservative
safety margin. Specifically, the parabola’s vertex shifts away from the robot’s origin in proportion to the relative distance, creating a more relaxed safety constraint compared to traditional
collision-cone
or
velocity-obstacle
approaches
while still guaranteeing
safety under input constraints
. This less restrictive formulation significantly improves the
feasibility
of the underlying CBF-based quadratic program (QP), particularly in dense environments where other methods often fail.
Motivation
[ICRA 2026] Dynamic Parabolic CBF
Conceptual illustration of the inner safe set and locally validated CBF parameter.
We present a novel theoretical framework for
online adaptation of Control Barrier Function (CBF) parameters
, i.e., the class K functions, under input constraints. To this end, we propose the concept of
locally validated CBF parameters
, where adapting these parameters ensures that the system trajectories remain safe within the
finite horizon
. (a) A candidate inner safe set defined via an Input Constrained CBF cannot be rendered forward invariant using the given CBF parameter. (b) With locally validated CBF parameters, the trajectory remains within the inner safe set over the finite horizon, ensuring safety for that interval. By adapting the CBF parameters, the corresponding inner safe set is reshaped dynamically,
alleviating conservatism
by allowing the trajectory to extend beyond a fixed, globally verified inner safe set.
Motivation
[CDC 2025] How to Adapt CBFs?
Baseline mapping (b) incorrectly labels obstacle voxels as free space due to odometry drift. Our certified map (c) deflates the reported safe region so that safety is preserved at every frame.
Accurate state estimation and mapping are prerequisites for safe navigation, yet most pipelines
assume perfect pose estimates
. Incremental drift in vision-based odometry (VIO/SLAM) can cause a map to misclassify obstacles as free space, leading to collisions.
We introduce a
certifiably-correct mapping framework
that
deflates
the claimed safe region at each timestep using the
covariance of the incremental pose estimate
. The deflation guarantees that the map stored in the robot’s body frame remains a subset of the true free space, even while global pose error grows unbounded.
Key points
•
Provably safe
: the shrunken set is
always a subset of the true free space
.
•
Two plugins:
1.
Certified-SFC:
deflates each face of a
Safe Flight Corridor (SFC)
polytope.
2.
Certified-ESDF:
subtracts a voxel-wise safety margin from an
ESDF
.
[RSS 2025] Certifiably-Correct Mapping
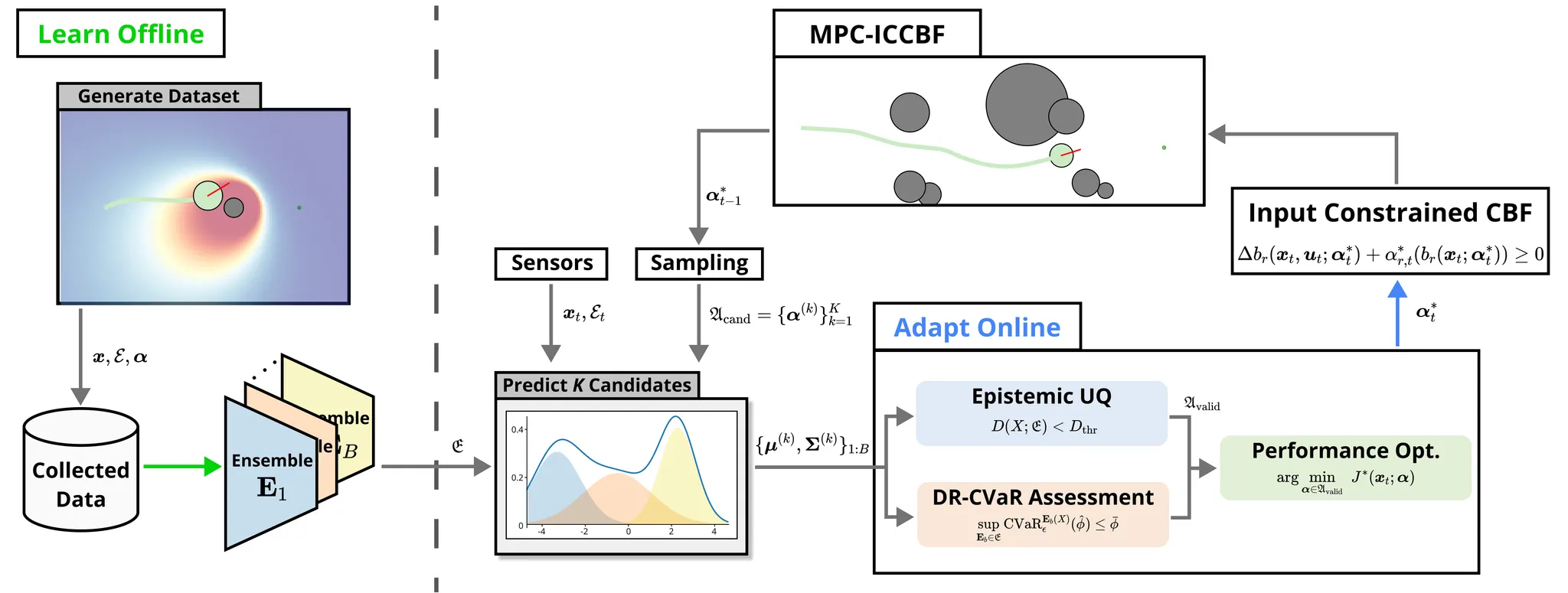
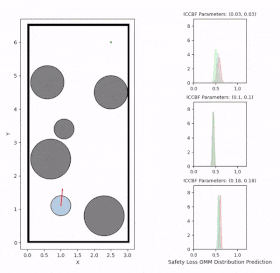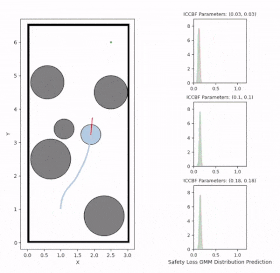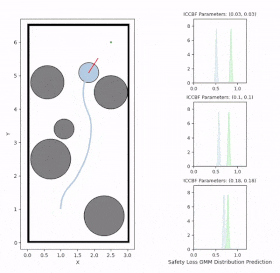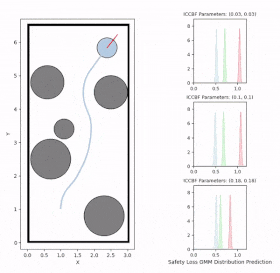
Overview diagram of the Online Adaptive ICCBF algorithm applied to MPC framework.
The
Online Adaptive ICCBF
algorithm dynamically adapts Input Constrained Control Barrier Function (ICCBF) parameters to optimize performance while ensuring safety for input-constrained nonlinear systems. Our approach leverages a
Probabilistic Ensemble Neural Network (PENN)
to predict performance and risk metrics, considering both
epistemic
and
aleatoric
uncertainties. The algorithm incorporates a two-step verification process using
Jensen-Rényi Divergence (JRD)
and
Distributionally-Robust Conditional Value at Risk (DR-CVaR)
to identify valid parameters. By adapting ICCBF parameters online based on the current state and nearby environment, our method
optimizes performance
while maintaining safety.
Motivation
[ICRA 2025] Online Adaptive ICCBF
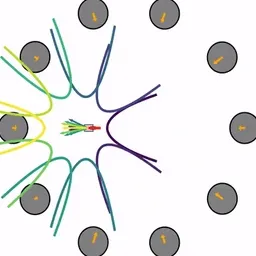
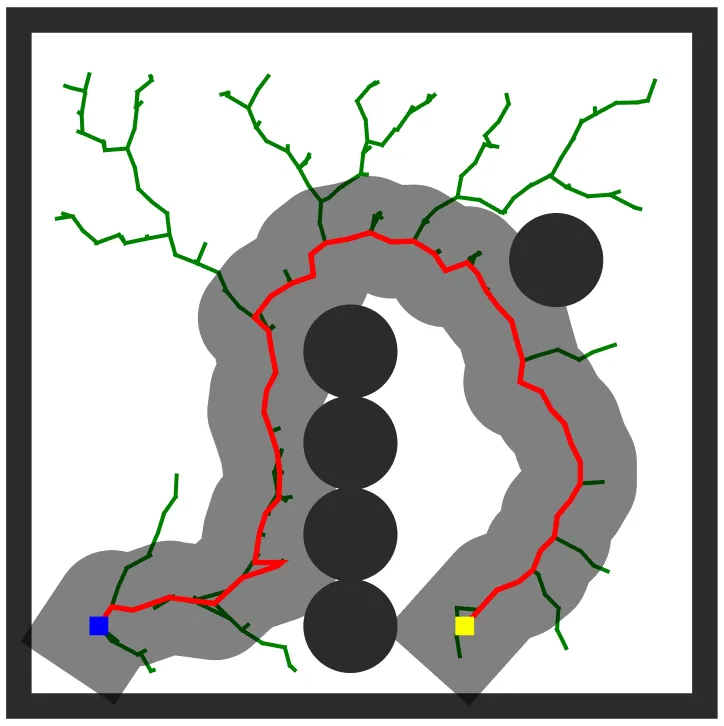
Main illustration of the Visibility-Aware RRT* algorithm.
The LQR-CBF-Steer function is used as a steering method in RRT* to generate safe trajectories between two nodes in the tree. Our
Visibility-Aware RRT*
algorithm incorporates two control barrier function (CBF) constraints into the LQR-CBF-Steer function to generate safe and efficient paths for robots with limited sensing capabilities. The
collision avoidance CBF
ensures the planned path remains collision-free w.r.t.
known obstacles
, while the novel
visibility CBF
guarantees the robot stays within locally collision-free regions, enabling timely detection and avoidance of
unknown obstacles
. These CBF constraints serve as termination criteria during the steering process, ensuring that the
generated paths are both collision-free and visibility-aware.
Motivation
[RA-L 2025] Visibility-Aware RRT*
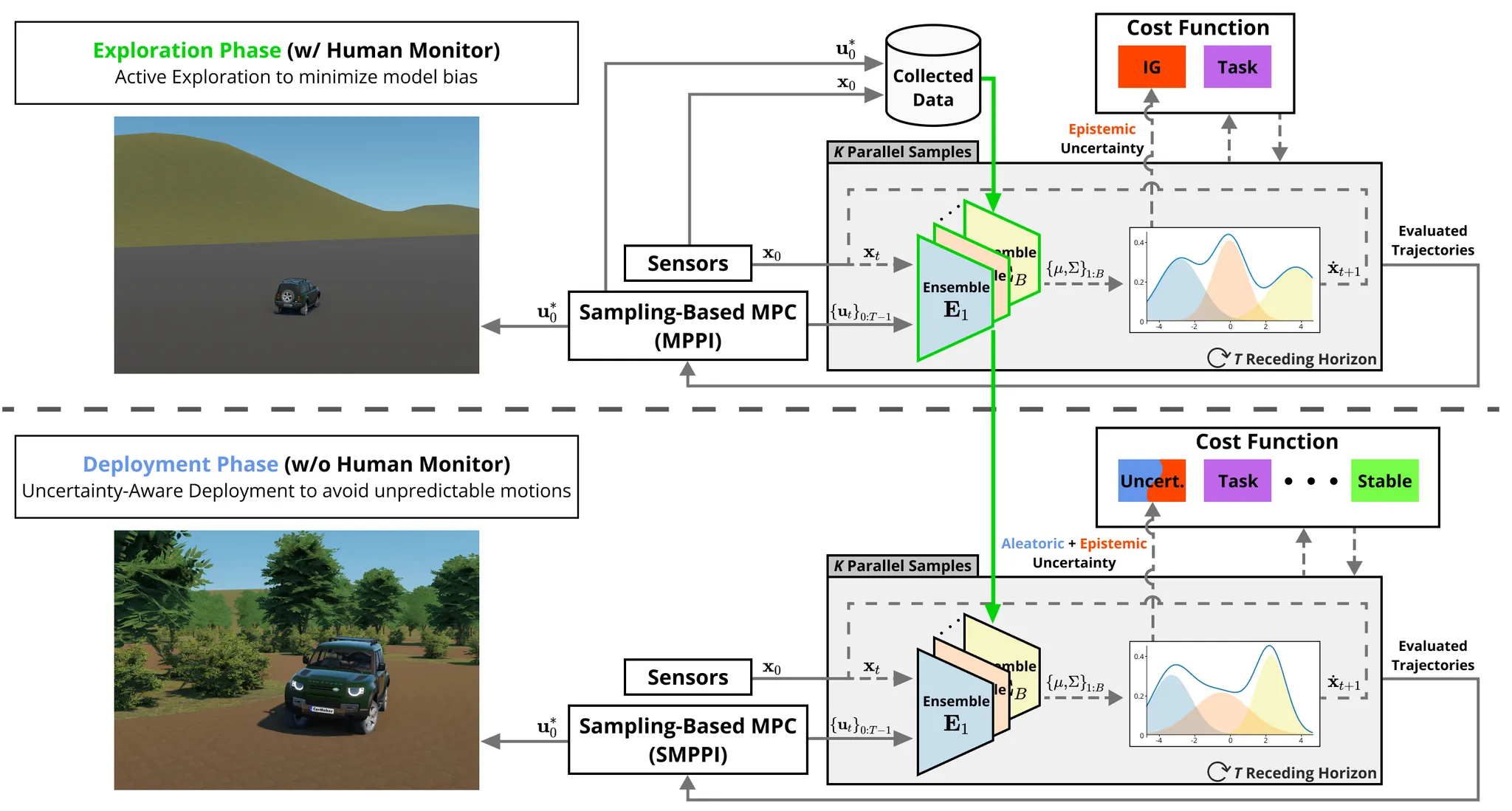
Overview diagram of our unified model-based reinforcement learning framework with dynamics learning. In
exploration phase
, a parallelized ensemble neural network serves as the robot dynamics and outputs the estimated posterior distribution of the next state. To enable active exploration, we quantify epistemic uncertainty by measuring the ensemble disagreement via Jensen-Rényi Divergence. In
deployment phase
, the neural network dynamics trained during the active exploration phase is applied directly to perform uncertainty-aware control. We transfer the neural network dynamics for uncertainty-aware deployment with minimal modification.
Video
[RSS 2023] Bridging Active Exploration and Uncertainty-Aware Deployment
Direct to the project page
홈
Hojin Lee*, Taekyung Kim*, Jungwi Mun, Wonsuk Lee (* equal contribution) AI and Autonomy Technology Center, Agency for Defense Development arXiv | video
[RA-L 2023] Learning Terrain-Aware Kinodynamic Model for Off-Road Driving
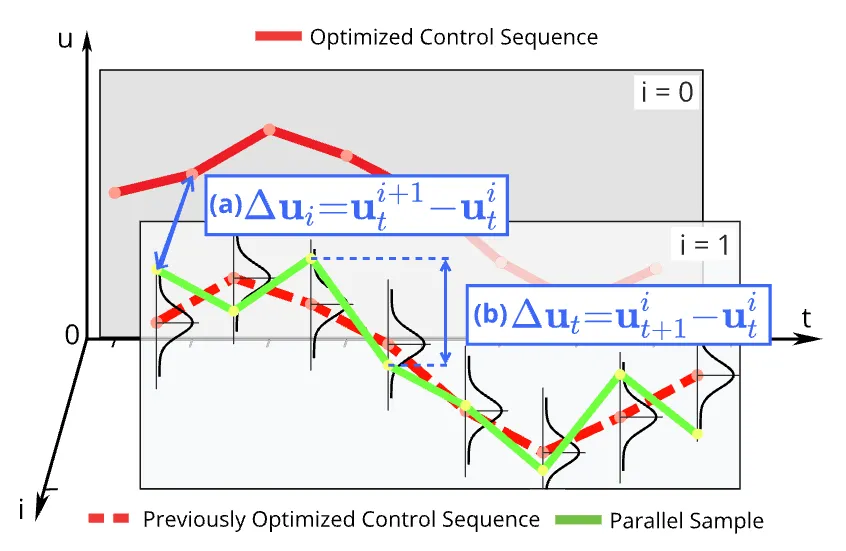
A simplified representation of the MPPI algorithm during each optimization iteration. For clarity, we only visualize one sampled trajectory (in green). (a) Amount of changes between previously computed control sequence and the next control sequence (along the “i-axis”). (b) Amount of changes in control values during MPPI rollouts (along the “t-axis”), which are hard to be minimized by the MPPI baseline. Such chattering in control input becomes more prominent in cases where the environment changes rapidly, possibly even causing the MPPI to diverge.
To address this issue, we propose the
Smooth MPPI
algorithm that seamlessly combines MPPI with an input-lifting strategy.
Frequently Asked Questions
Q:
How to tune Δt in Smooth MPPI?
[RA-L 2022] Smooth MPPI
Other Projects
Traversability Estimation
Deep Learning
Traversability
Off-Road Autonomous Driving
Dynamic Learning
Uncertainty-Aware Active Exploration
MBRL
Dynamic Learning
Learning-Based Vehicle Model and Control
Dynamic Learning
Control
Smooth MPPI
Control
DPoom
Robot System
Navigation

 Other Projects
Other Projects

.png&blockId=26818d5c-31e3-8110-90d3-cebd17860fef)
.svg&blockId=27718d5c-31e3-80a8-8ef8-fff9b3306340)


.png&blockId=20d18d5c-31e3-80f7-a433-cf95527225b9)


.png&blockId=b5e9a59f-17a0-408d-8ff2-3b1d12359528)